Chapter 2 Data
2.1 Data Source
Our data includes financial information on companies in the S&P 500 stock index from 1999-2021. This information was scraped from Yahoo Finance in November of 2021, and collected in a csv format for data analysis.
To collect the data, first, we got the list of the current 500 S&P companies from Slickchart (https://www.slickcharts.com/sp500). After having the list of the companies, we then moved on to the financial information of the listed companies on yahoo finance (https://finance.yahoo.com/) to get the metrics such as sales, earnings, cogs, stock price, and market sector. We then scraped the data using the BeautifulSoup library in Python and turned that into a CSV file.
Our main goal is to analyze and model this data to better improve projections for a company’s future metrics, like earnings.
2.2 Variables
The main variables that are used in this project are defined below:
| Variable | Meaning |
|---|---|
| YEAR | The financial year of the company |
| COMPANY | The company’s stock abbreviation symbol |
| MARKET.CAP | The total market capitalization of the company (Volume * Price) |
| EARNINGS | The earnings in dollars for the previous year for the given company |
| SALES | How much the company sold in dollars last year |
| CASH | How much cash the company has in dollars at the end of the previous year |
| Name | The full name of the company |
| Sector | The name of the sector that the company is a part of |
| Earnings_next_year | The amount of money in dollars that the company earns in the following year |
| EARNINGS_1_YEAR_AGO | The amount of money in dollars that the company earned in the previous year |
2.3 Data Cleaning
2.3.1 Data Pre-Processing
First, as earnings, cash, and other variables are really large, we have decided to divide them by 1 billion. The reason for this is to make it easier to interpret and to understand the model.
#Scaling Variables of Interest
data <- data %>%
mutate(EARNINGS_Scaled = EARNINGS/1000000000,
CASH_Scaled = CASH/1000000000,
MARKET.CAP_Scaled = MARKET.CAP/1000000000,
Earnings_next_year_Scaled = Earnings_next_year/1000000000,
SALES_Scaled = SALES/1000000000)Next, we added lagged variables for earnings and sales as we believe information from previous years will help predict future metrics.
#Adding Lagged Variables
data <- data %>%
group_by(COMPANY) %>%
mutate(EARNINGS_1_YEAR_AGO = lead(EARNINGS_Scaled, n = 1),
EARNINGS_2_YEAR_AGO = lead(EARNINGS_Scaled, n = 2),
EARNINGS_3_YEAR_AGO = lead(EARNINGS_Scaled, n = 3),
EARNINGS_4_YEAR_AGO = lead(EARNINGS_Scaled, n = 4)) %>%
mutate(SALES_1_YEAR_AGO = lead(SALES_Scaled, n = 1),
SALES_2_YEAR_AGO = lead(SALES_Scaled, n = 2),
SALES_3_YEAR_AGO = lead(SALES_Scaled, n = 3),
SALES_4_YEAR_AGO = lead(SALES_Scaled, n = 4))2.3.2 Graphing Outliers
We will do some more basic exploration regarding our data set, particularly our dependent variable of interest: Earnings next year. Earnings_next_year_Scaled is the company’s earnings the next year, so a value of 1 for Company X in 2015 can be interpreted as Company X had 1 billion dollars in earnings in 2016.
We explore Earnings next year below:
#Graphing Outliers
data %>% ggplot(aes(x = Earnings_next_year_Scaled)) +
geom_boxplot()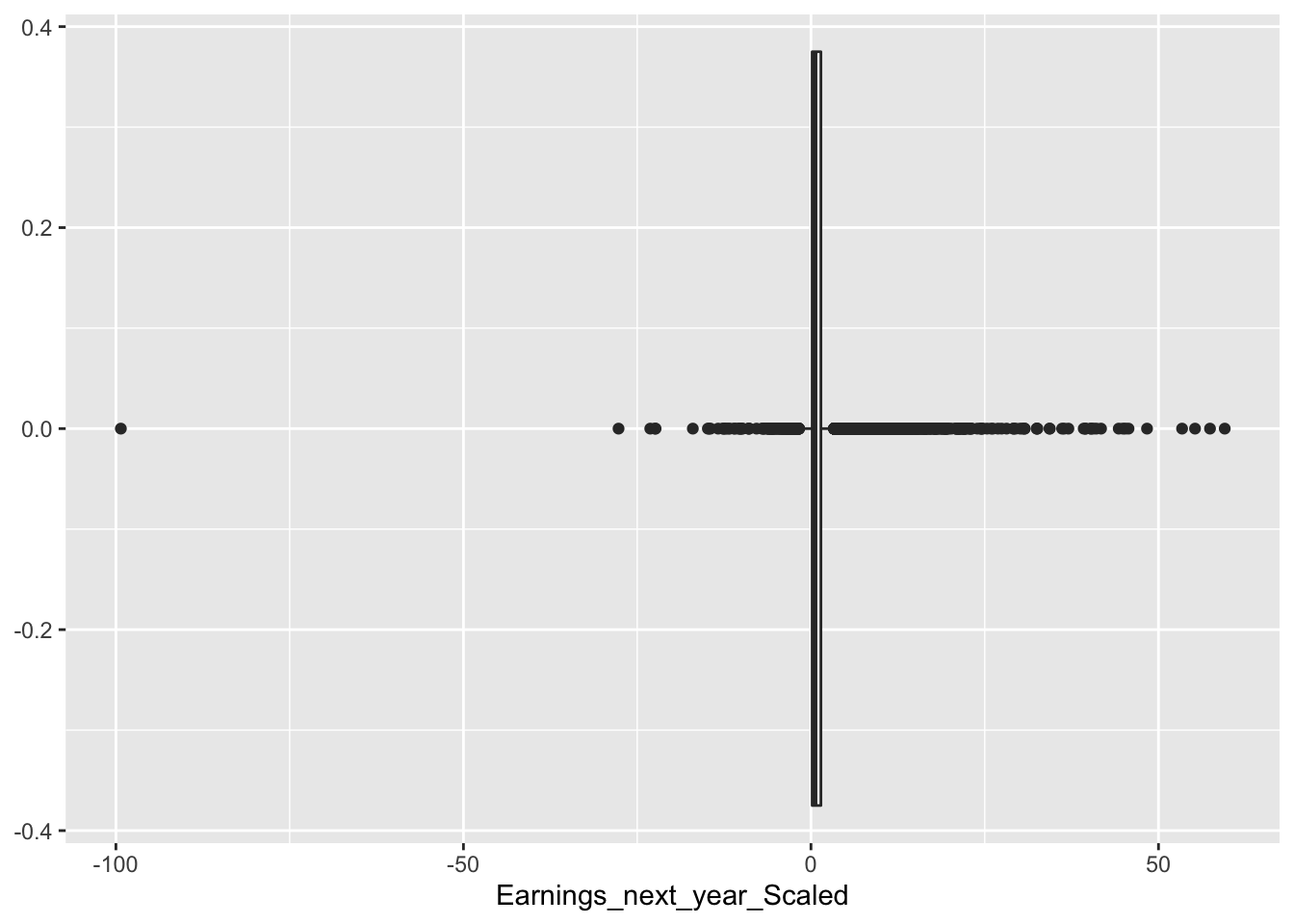
data %>% ggplot(aes(x = EARNINGS_Scaled, y= Earnings_next_year_Scaled))+
geom_point()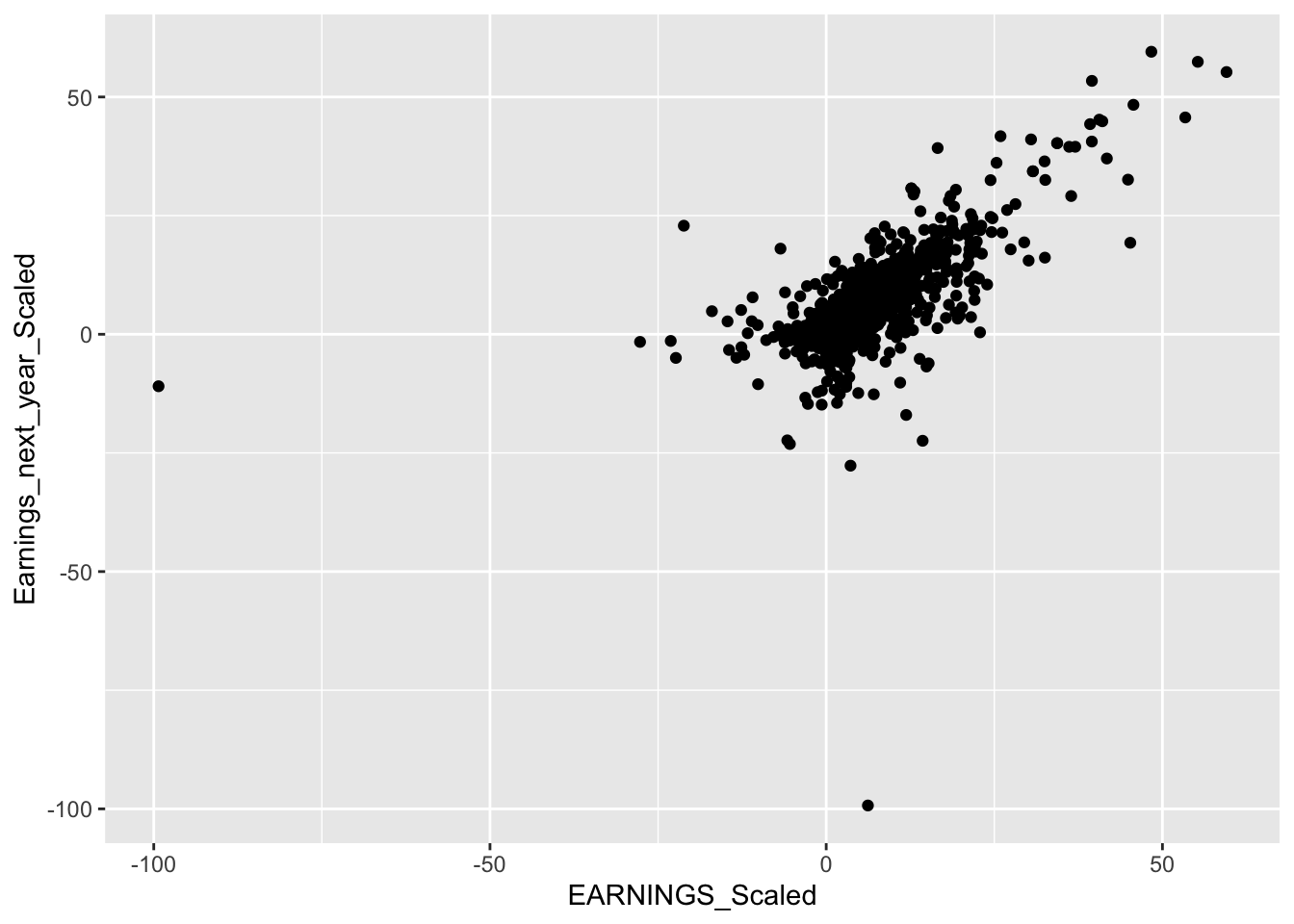
There are a high number of outliers in our data, this is not ideal as we do not want to fit a model that includes many outliers, as predicting and modeling these posterior distributions would be quite difficult.
We decided to remove outliers by classifying them as one if they are outside the range of +/- (0.9 * IQR) (Interquartile Range).
Q <- quantile(data$Earnings_next_year_Scaled, probs=c(.25, .75), na.rm = TRUE)
iqr <- IQR(data$Earnings_next_year_Scaled, na.rm = TRUE)
up <- Q[2]+.90*iqr # Upper Range
low<- Q[1]-.90*iqr # Lower Range
eliminated<- subset(data, data$Earnings_next_year_Scaled > (low) & data$Earnings_next_year_Scaled < (up))
data_elimatedO <- eliminatedWe graph the remaining data points without outliers below:
data_elimatedO %>% ggplot(aes(x = Earnings_next_year_Scaled)) +
geom_boxplot()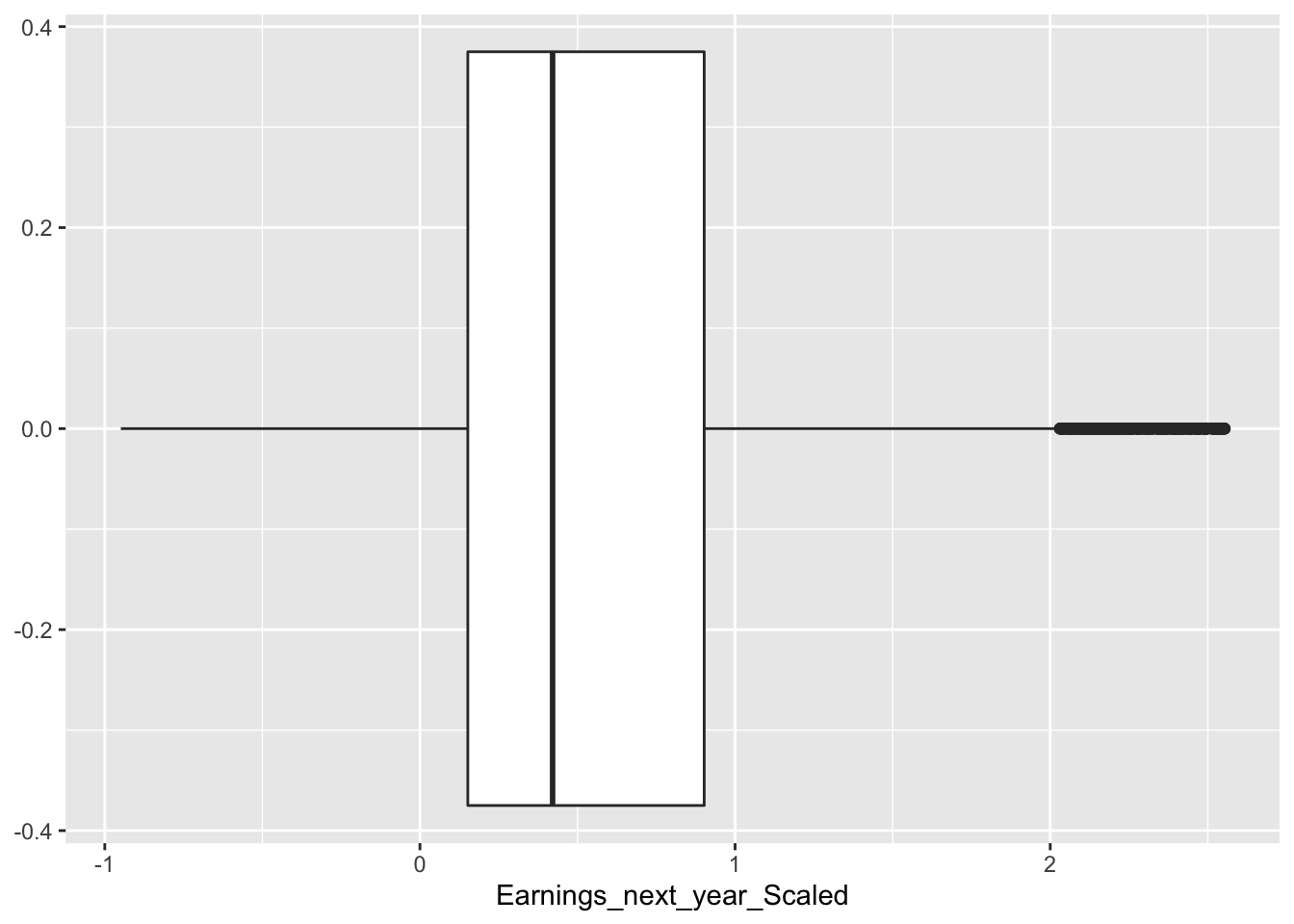
data_elimatedO %>% ggplot(aes(x = EARNINGS_Scaled, y= Earnings_next_year_Scaled))+
geom_point()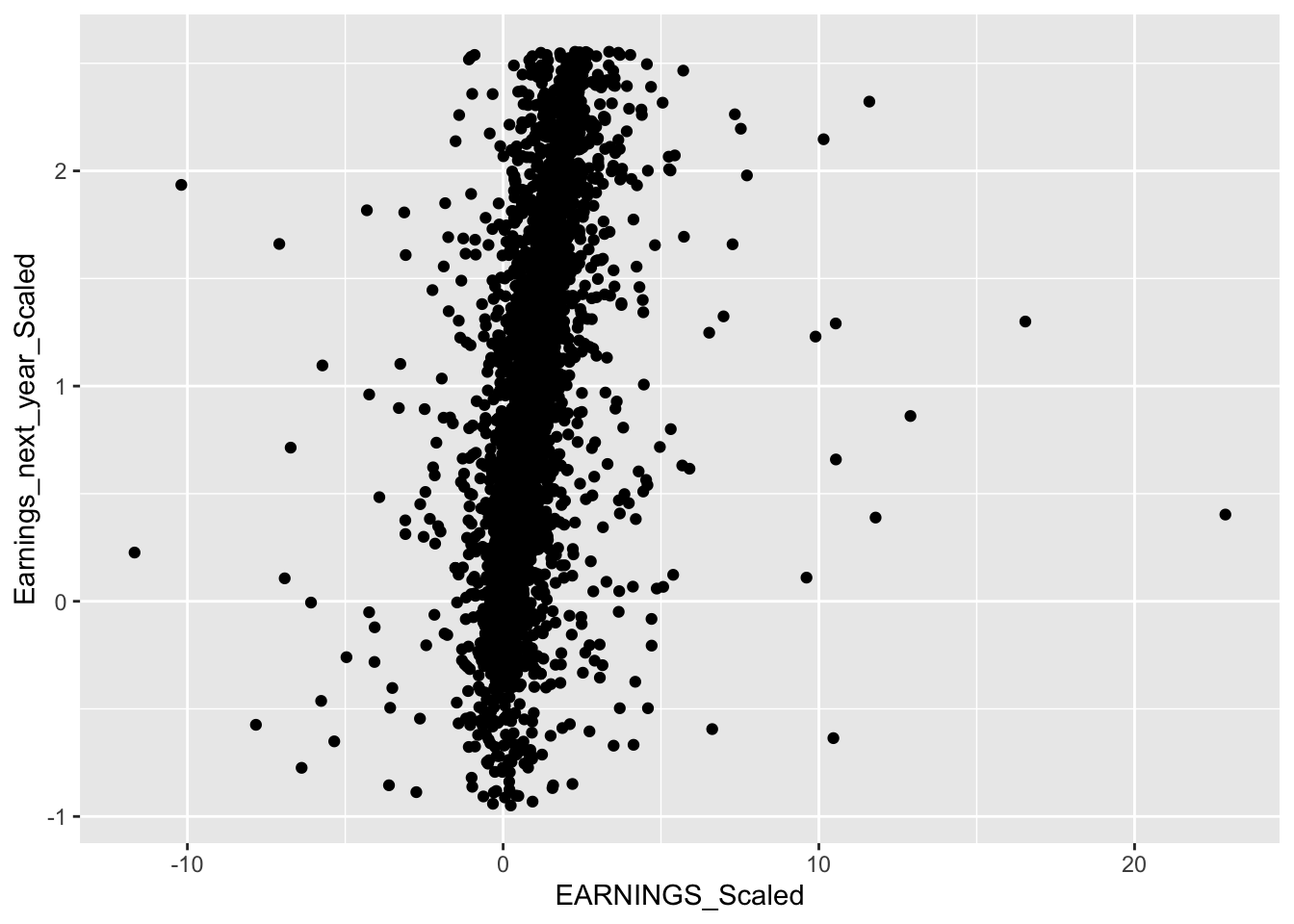
This is much better as the data points are closer in proximity.
2.4 Initial Explorations
After cleaning the data, we then did some initial explorations like looking at the distribution of the companies within the S&P 500. The first plot we are going to create is the number of companies within the given time period:
tabyl(data$YEAR) %>%
ggplot(aes(x= `data$YEAR`, y = n)) +
geom_line() +
labs(title = "Number of Companies Within the Period", x = "", y = "") +
theme_minimal()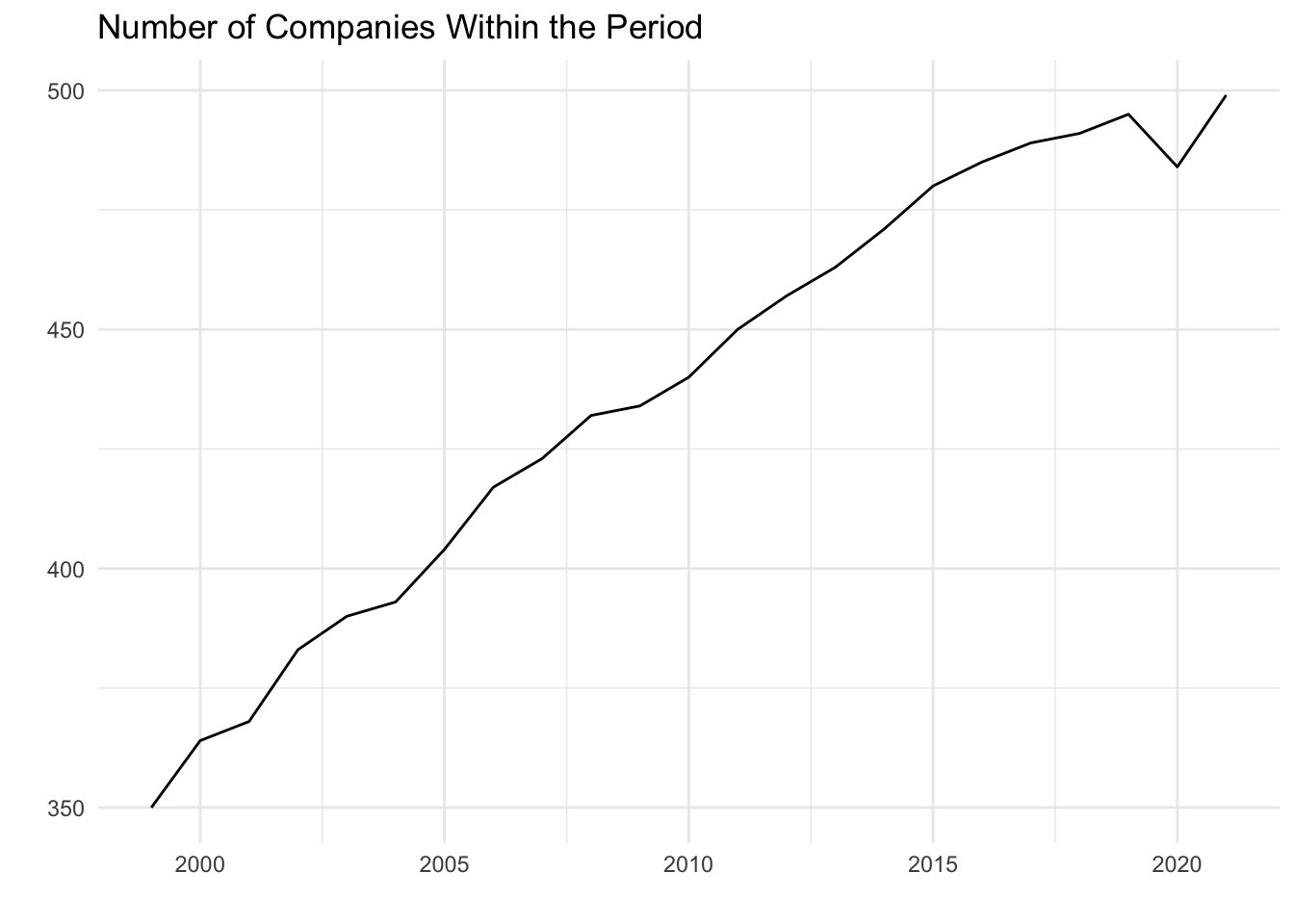
As we see above, we have data for about 70% of the companies in the S&P 500 for the first year of our data, and by 2021 we have about every single company within the index. It is important for us to have data on as many companies as possible over this time period so that we can better capture trends and make more accurate models based on the data.
sumUSA <- data %>%
group_by(YEAR) %>%
summarise(sumMarket_cap = sum(`MARKET.CAP`),
sumEarnings = sum(EARNINGS),
sumSALES = sum(SALES),
sumCASH = sum(CASH))
sumUSA %>%
ggplot(aes(x = YEAR, y = sumMarket_cap)) +
geom_line() +
theme_minimal() +
labs(x = "Year", y = "Sum of Market Cap", title = "Market Cap within Dataset")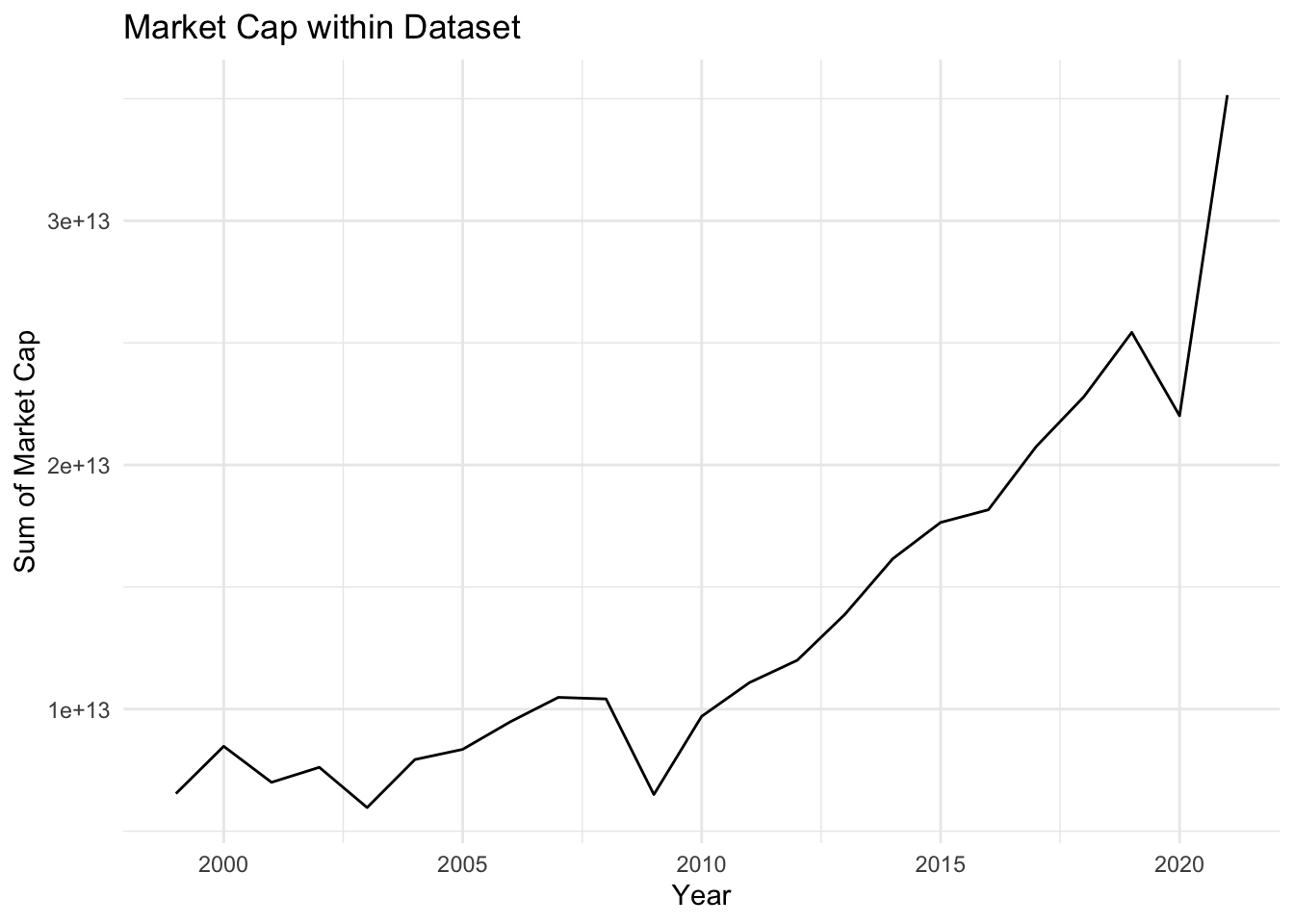
Next, we investigated how market cap, specifically the sum of all the companies’ market caps, varied from year to year. By grouping by year, we were able to easily combine each companies market cap together to create the plot above. This plot highlights trends in the overall market, we see a general increase over time in market cap, with sharp decreases around 2008 and 2020. Those two years align with the housing market crash and the emergence of COVID-19 respectively, both which led to decreases in the overall stock market. By identifying trends in the overall market, we may have a better idea about how individual companies may perform.
temp <- data %>%
group_by(COMPANY) %>%
summarize(count = n(),
mean_MC = mean(MARKET.CAP)) %>%
filter(count == 23) %>%
arrange(desc(mean_MC)) %>%
head(50)
temp <- temp$COMPANY
data_2 <- data %>%
filter(COMPANY %in% temp)
data_2 %>%
ggplot(aes(y = EARNINGS, x= SALES, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("Sales and Earnings Relationship by Sector \n Among top 50 Companies by Market Cap")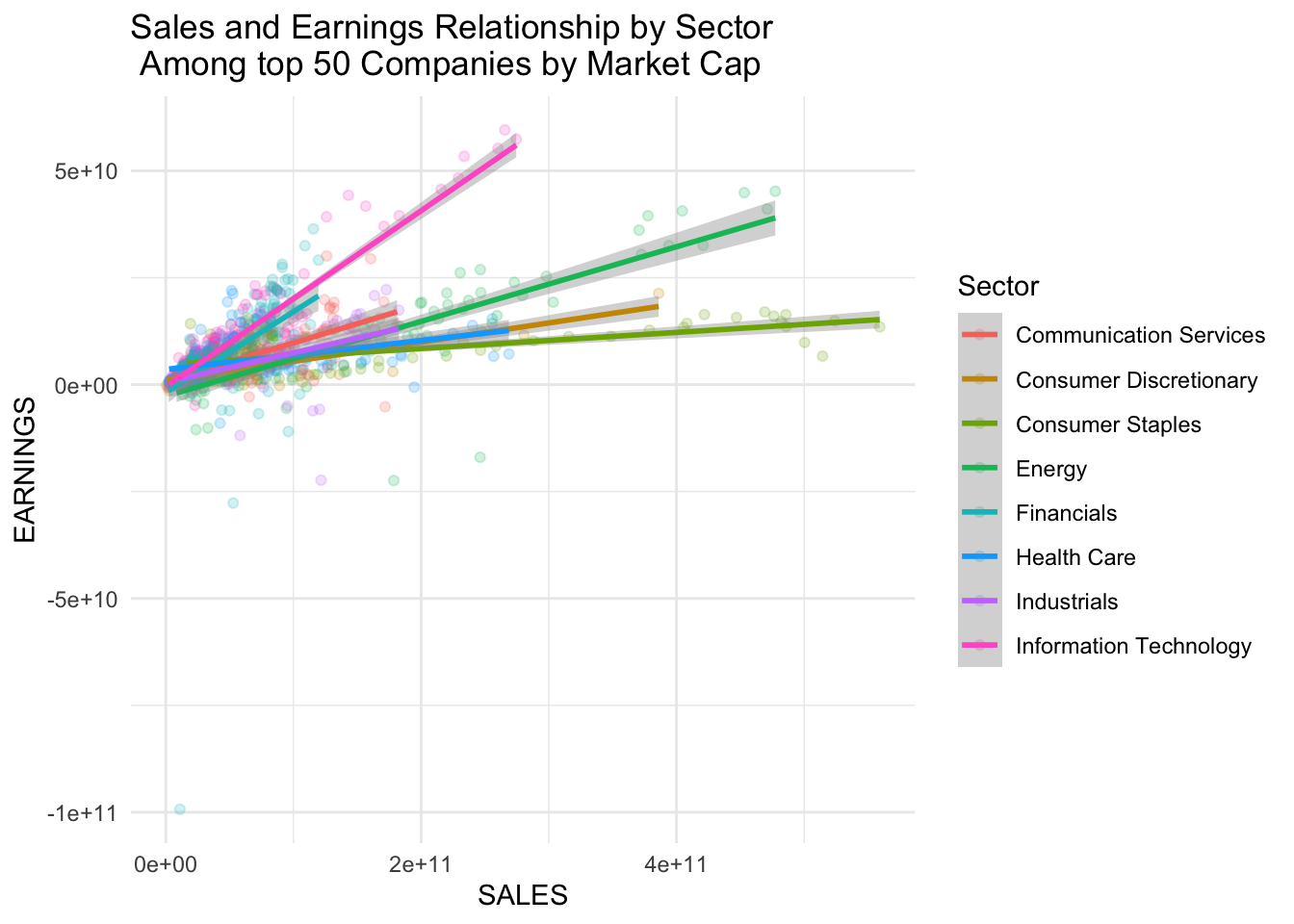
Our main objective with this project is to be able to accurately predict future earnings using metrics like sales, previous earnings, and other variables like the sector of the company. We found that overall, among the top 50 companies (based on market cap), there were positive relationships between earning and sales. This relationship varies based on the market sector, with IT having the most positive relationship, and Consumer Staples having the least positive relationship. This indicates to us that both sector and sales may be important predictors of earnings that we should explore using in our future models.
p1 <- data %>%
ggplot(aes(y = Earnings_next_year_Scaled, x= EARNINGS_Scaled, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("Same Year")
p2 <- data %>%
ggplot(aes(y = Earnings_next_year_Scaled, x= EARNINGS_1_YEAR_AGO, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("1 year ago")
p3 <- data %>%
ggplot(aes(y = Earnings_next_year_Scaled, x= EARNINGS_2_YEAR_AGO, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("2 year ago")
p4 <- data %>%
ggplot(aes(y = Earnings_next_year_Scaled, x= EARNINGS_3_YEAR_AGO, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("3 year ago")
p5 <- data %>%
ggplot(aes(y = Earnings_next_year_Scaled, x= EARNINGS_4_YEAR_AGO, color = Sector))+
geom_point(alpha = 0.20)+
geom_smooth(method = 'lm', formula = y ~ x)+
theme_minimal()+
ggtitle("4 year ago")
ggarrange(p1, p2, p3, p4, p5,
ncol = 3, nrow = 2,
common.legend = TRUE, legend = "bottom")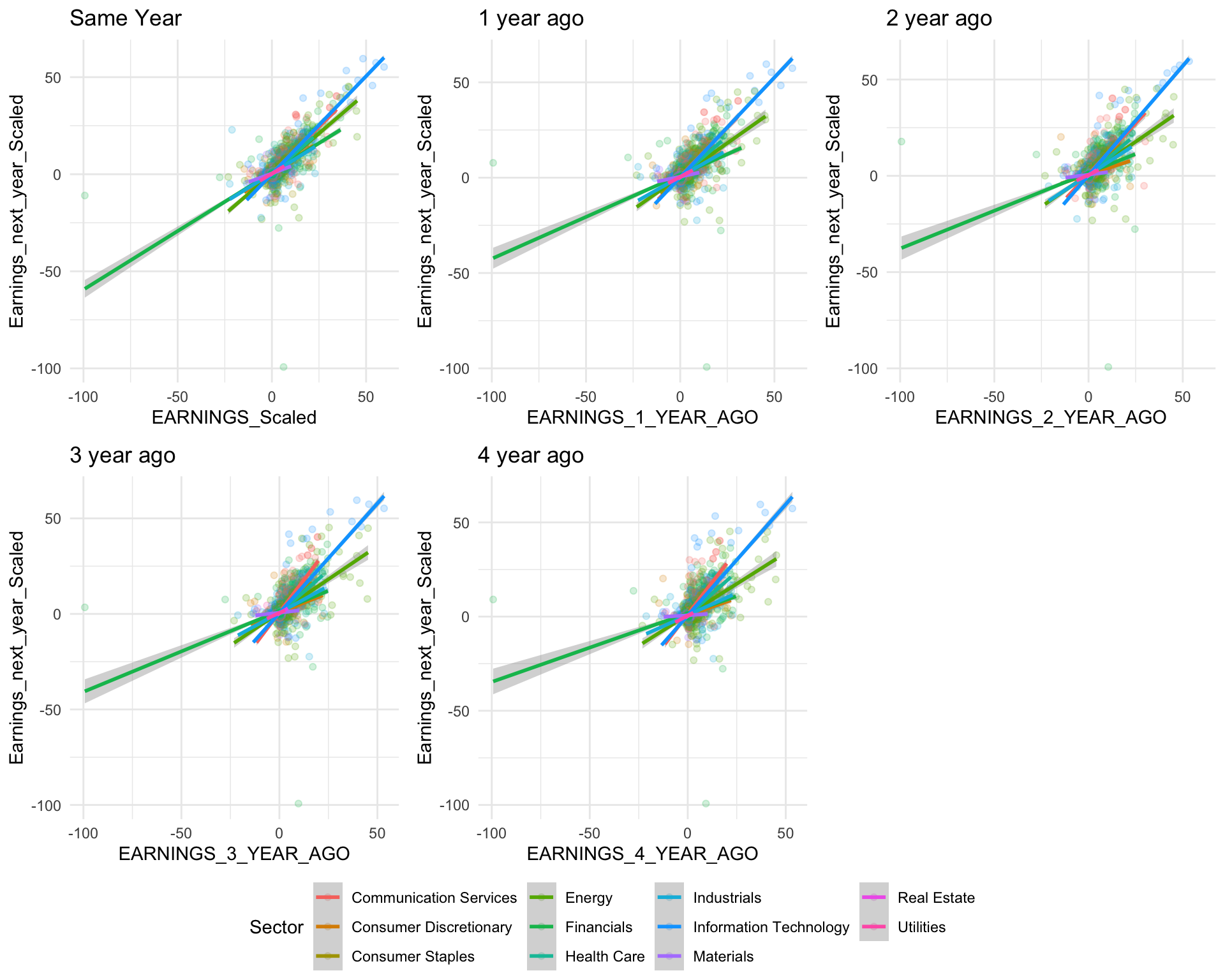
For most sectors, it appears that the farther back we go, the flatter the relationship between Earnings and past earnings is. If we plot earnings next year with earnings four years ago, we will see that almost all sectors have different slopes. This indicates to us that more recent years (earnings 1 year ago, 2 years ago, etc.) will be more useful in our models than less recent years (earnings 4 years ago, 5 years ago, etc.)